内存, mem
内存对于缓存更新策略,要区分Write-Through和Write-Back两种策略。前者更新内容直接写内存并不同时更新Cache,但要置Cache失效,后者先更新Cache,随后异步更新内存。通常X86 CPU更新内存都使用Write-Back策略。
虚拟内存
虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续可用的内存 (一个连续完整的地址空间) ,而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。与没有使用虚拟内存技术的系统相比,使用这种技术的系统使得大型程序的编写变得更容易,对真正的物理内存 (例如RAM) 的使用也更有效率。 注意: 虚拟内存不只是「用磁盘空间来扩展物理内存」的意思——这只是扩充内存级别以使其包含硬盘驱动器而已。把内存扩展到磁盘只是使用虚拟内存技术的一个结果,它的作用也可以通过覆盖或者把处于不活动状态的程序以及它们的数据全部交换到磁盘上等方式来实现。对虚拟内存的定义是基于对地址空间的重定义的,即把地址空间定义为「连续的虚拟内存地址」,以借此「欺骗」程序,使它们以为自己正在使用一大块的「连续」地址。
为什么要使用虚拟内存 a. 产生的背景
(摘自书籍Rechnerarchitektur : Von der digitalen Logik zum Parallelrechner 作者Andrew S. Tanenbaum )早期的计算机内存容量非常小,通常只能存储几千个Wörter 1(即数据单元),但价格却是十分昂贵。(之后的Beispiele是指一些关于早期计算机的具体例子) 所造成的不便: a. 使用这些容量很小的内存,导致了程序运行的速度很慢,原因是在于存放相对高效的算法需要占用的内存空间相对较大,所以程序员们只能使用执行效率较低的,但是占用内存容量较小的算法。à对于这个问题的传统解决方案是,(物理上,或者说在硬件上)新增加一个(或多个)内存空间(例如,硬盘- Plattenspeicher)。b. 而同时还造成的一个不便之处,是在这种内存容量很小的情况下,程序员需要人为地将程序分解成为多个部分(Overlays), 然后分开来存储进内存中。在执行程序时,就首先执行第1个Overlay, 执行完毕后,继而调用第2个Overlay,以此类推。à进展:尽管这个方法在那个时代已经很广泛地普及化了,但是由于使用Overlay进行管理执行程序的办法需要大量的人力投入,这其中的成本仍是不容小觑的。于是在1961年,一位来自英国曼彻斯特的研究人员提议,不如将程序通过Overlays执行这个方法设计成自动化的模式,这样就无需程序员费劳管理程序的划分与安置的任务。这个新的方法所使用到的一个新的概念即是虚拟内存virtueller Speicher。b.使用虚拟内存的优势: (摘自https://blog.csdn.net/vernice/article/details/41783601) 1 程序员无需操心如何存储(数据,程序等等的)内容。2 通过分布在同一个物理内存空间的两个不同的区间,虚拟内存里的数据和程序可以彼此共享使用3 它使得应用程序在系统中可以更自如地在物理地址中被执行。虚拟内存的操作过程是怎么样的
假如说这台机器不适用虚拟内存这个概念,那么程序就会报错,例如"该指定的地址范围在内存中不存在",继而程序终止执行。而反过来若是这台机器是适用虚拟内存的,那么这个任务会按照如下步骤来执行: 1 寻找位于存储盘上,介于地址8192和12287之间的数据单元。2 将这段原来地址为8192~12287的数据单元加载到内存中。3 而这段数据对应到内存中的地址将被定义为0~4095。4 而程序将继续正常地执行下去。 人们将这项自动划分区间(Overlays)的技术命名为Paging (deuts. Seitenauslagerung),而这一段段从硬盘中读出来的程序区间即被命名为Page (deuts. Seiten)。
虚拟地址通过对虚拟地址空间到物理地址空间的一个动态映射来实现。而虚拟的地址空间也会相应地划分成Pages, 然后整个虚拟地址空间就相当于一张划分地址空间的表格,与实际的物理内存地址相互对应。 (只是这个图像的内存中没有包含多个4KB的内存空间,而是指设置了一个,所以这个具例中,我们只能一次对应一个4KB的空间。)
而这个对应的关系实际上也可以更为的复杂,这是完全可以做到的。我们一方面将存储程序的地址称为虚拟地址空间Adressraum (Virtual Address Space),另一方面将真正存在的,有线路控制的内存地址称作物理地址空间(Physical Address Space)。依据对应的物理地址空间规划虚拟地址空间上的内容区划。这里我们假设首先是有足够的空间来装得下虚拟的地址空间的。这样人们就会获得一种假象,这种假象会让人感到好像有十分充足的(物理)内存空间一样,但实际上这些都是因为虚拟内存这个概念的应用,而现实中物理内存的实际容量远远少于人们所需要的。
有了这个优势,程序就可以任意地将虚拟地址空间里的数据加载出来,或者将新的数据存储到虚拟的内存空间中去,而人们也完全无需去顾虑是否物理内存的容量是否够用。
(有的)程序员甚至可以完全不需要知道虚拟内存的存在。计算机于是看上去是有一个很大很大的内存的。
而实现虚拟内存的一个本质前提是要有一个可以存放整个程序和数据的硬盘。这一个硬盘可以是可以转动的那种硬盘,也可以是固态硬盘。在书中我们统一将"Platte"或者说"Festplatte" 理解为固态硬盘。(将存在硬盘里的程序作为原件,而将程序数据转运到内存中所要做的即是一个复制的功能)自然的,在执行操作后要保持对硬盘里的程序(即原件)的更新。当在内存中原数据的"副本"改变后,反过去就要对硬盘的程序进行改动。
内存管理单元,内存控制单元 (MMU)
什么是MMU MMU(Memory Management Unit)主要用来管理虚拟存储器、物理存储器的控制线路,同时也负责虚拟地址映射为物理地址,以及提供硬件机制的内存访问授权、多任务多进程操作系统。 (来自百度百科,对其几个点不熟悉,因此可以只考虑加粗部分)
发展历史 注意: 学习一个知识点,很重要的一步是了解其为什么而存在?它的存在是为了解决什么问题?然后,在学习的过程中带着这些问题去理解、去思考。
在许多年以前,还是使用DOS或一些古老的操作系统时,内存很小,同时,应用程序也很小,将程序存储在内存中基本能够满足需要。随着科技的发展,图形界面及一些其他更复杂的应用出现,内存已经无法存储这些应用程序了,通常的解决办法是将程序分割成很多个覆盖块,覆盖块0最先运行,运行结束之后,就调用另一个覆盖块,虽然这些操作由OS来完成,但是,需要程序员对程序进行分割,这非常不高效;因此,人们想出了一个虚拟存储器 (virtual memory) 的方法。虚拟存储器的基本思想是: 程序、数据、堆栈的总大小可以超过内存空间的大小,操作系统将当前运行的部分保存在内存中,未使用的部分保存在磁盘中。比如一个16MB的程序和一个内存只有4MB的机器,操作系统通过选择可以决定哪部分4MB的程序内容保存在内存中,并在需要时,在内存与磁盘中交换程序代码,这样16MB的代码就可以运行在4MB的机器中了。注意: 这里面包含了虚拟地址和物理地址的概念
相关概念 地址范围、虚拟地址映射成物理地址以及分页机制
地址范围: 指处理器能够产生的地址集合,如一个32bit的处理器ARM9,其能产生的地址集合是0x0000 0000 ~ 0xffff ffff(4G),这个地址范围也称为虚拟地址空间,其中对应的地址为虚拟地址。 虚拟地址与物理地址: 与虚拟地址空间和虚拟地址相对应的是物理地址空间和物理地址;物理地址空间只是虚拟地址空间的一个子集。如一台内存为256MB的32bit X86主机,其虚拟地址空间是0 ~ 0xffffffff(4GB),物理地址空间范围是0 ~ 0x0fff ffff(256M) 分页机制: 如果处理器没有MMU,或者有MMU但没有启用,CPU执行单元发出的内存地址将直接传到芯片引脚上,被内存芯片 (以下称为物理内存,以便与虚拟内存区分) 接收,这称为物理地址 (Physical Address,以下简称PA) ,如下图3-1-1所示;
图3-1-1 未使用MMU.png
如果处理器启用了MMU,CPU执行单元发出的内存地址将被MMU截获,从CPU到MMU的地址称为虚拟地址 (Virtual Address,以下简称VA) ,而MMU将这个地址翻译成另一个地址发到CPU芯片的外部地址引脚上,也就是将VA映射成PA,,如下图3-1-2。
图3-1-2 使用了MMU.png 大多数使用MMU的机器都采用分页机制。虚拟地址空间以页为单位进行划分,而相应的物理地址空间也被划分,其使用的单位称为页帧,页帧和页必须保持相同,因为内存与外部存储器之间的传输是以页为单位进行传输的。例如,MMU可以通过一个映射项将VA的一页0xb70010000xb7001fff映射到PA的一页0x20000x2fff,如果CPU执行单元要访问虚拟地址0xb7001008,则实际访问到的物理地址是0x2008。
虚拟内存的哪个页面映射到物理内存的哪个页帧是通过页表 (Page Table) 来描述的,页表保存在物理内存中,MMU会查找页表来确定一个VA应该映射到什么PA。
功能 执行过程 操作系统和MMU是这样配合的:
操作系统在初始化或分配、释放内存时会执行一些指令在物理内存中填写页表,然后用指令设置MMU,告诉MMU页表在物理内存中的什么位置。
设置好之后,CPU每次执行访问内存的指令都会自动引发MMU做查表和地址转换操作,地址转换操作由硬件自动完成,不需要用指令控制MMU去做。
重要: 我们在程序中使用的变量和函数都有各自的地址,在程序被编译后,这些地址就成了指令中的地址,指令中的地址就成了CPU执行单元发出的内存地址,所以在启用MMU的情况下, 程序中使用的地址均是虚拟内存地址,都会引发MMU进行查表和地址转换操作。 (注意理解这句话)
内存保护机制 处理器一般有用户模式 (User Mode) 和特权模式 (privileged Mode) 之分。操作系统可以在页表中设置每个页表访问权限,有些页表不可以访问,有些页表只能在特权模式下访问,有些页表在用户模式和特权模式下都可以访问,同时,访问权限又分为可读、可写和可执行三种。这样设定之后,当CPU要访问一个VA (Virtual Address) 时,MMU会检查CPU当前处于用户模式还是特权模式,访问内存的目的是读数据、写数据还是取指令执行,如果与操作系统设定的权限相符,则允许访问,把VA转换成PA,否则不允许执行,产生异常 (Exception) 。
异常与中断: 异常与中断的处理机制类似,不同的是中断由外部设备产生,而 异常由CPU内部产生的;中断产生与CPU当前执行的指令无关,而异常是由于当前执行的指令出现问题导致的
通常操作系统会将虚拟地址空间划分为用户空间和内核空间。例如x86平台的linux系统的虚拟地址空间范围是0x0000 0000 ~ 0xffff ffff,前3G的空间为用户空间,后1G的空间为内核空间。用户程序加载到用户空间,内核程序加载到内核空间,用户程序不能访问内核中的数据,也不能跳转到内核空间执行。这样可以保护内核,如果一个进程访问了非法地址,顶多就是这个进程崩溃,而不会影响到内核和系统的稳定性。在系统发生中断或异常时,不仅会跳转到中断或异常服务函数中执行,而且还会从用户模式切换到特权模式,从中断或异常服务程序跳转到内核代码中执行。总结一下: 在正常情况下处理器在用户模式执行用户程序,在中断或异常情况下处理器切换到特权模式执行内核程序,处理完中断或异常之后再返回用户模式继续执行用户程序。
段错误我们已经遇到过很多次了,它是这样产生的:
用户程序要访问的一个VA,经MMU检查无权访问。 MMU产生一个异常,CPU从用户模式切换到特权模式,跳转到内核代码中执行异常服务程序。 内核把这个异常解释为段错误,把引发异常的进程终止掉。 S3C2440/S3C2410 中的MMU S3C2440/S3C2410 MMU概述 S3C2440的MMU使用页表来实现虚拟地址到物理地址的转换;页表存储在内存中,页表中的每一行对应于虚拟存储空间的一个页,该行包含了该虚拟内存页对应的物理内存页的地址、该页的方位权限和该页的缓冲特性等。这里页表中的每一行称为一个地址变换条目 (entry) 也称为"描述符"。描述符有: 段描述符、大页描述符、小页描述符、极小页描述符——他们保存段、大页、小页或极小页的起始物理地址;粗页表描述符、细页表描述符——它们保存二级页表的物理地址。
页表的存储: 页表存放在内存中,系统通常有一个寄存器来保存页表的基地址。在ARM中系统控制协处理器CP15的寄存器C2用来保存页表的基地址。
TLB, Translation Lookaside buffer
因为从虚拟地址到物理地址的变换过程是通过查询页表完成的,而页表又存储在内存中,如果每次程序执行时去读取内存中的数据获取物理地址,代价很大。而程序在执行过程中可能只对页表中的少数几个单元进行访问,根据这一特点,采用一个容量更小 (通常为8~16个字) 、访问速度和CPU中通用寄存器相当的存储器件来存放当前访问需要的地址变换条目。这个小容量的页表称为TLB (Translation Lookaside buffer) 。
S3C2440/S3C2410中的页表 在S32440/S3C2410中最多会使用两级页表: 以段 (Section 1MB) 的方式进行转换时只用到一级页表,以页 (Page) 的方式进行转换时用到二级页表。
CPU 访问内存的过程:
- 当CPU需要访问内存时,先在TLB中查询需要的地址变换条目。如果该条目不存在,CPU从位于内存中的页表中查询,并把相应的结果添加到TLB中。这样,当CPU下一次又需要该地址变换条目时,可以从TLB中直接得到,从而使地址变换的速度大大加快。
- 当内存中的页表内容改变,或者通过修改系统控制协处理器CP15的寄存器C2使用新的页表时,TLB中的内容需要全部清除。系统控制协处理器CP15的寄存器C8用来控制清除TLB内容的相关操作。
- MMU 可以将某些地址变换条目锁定在TLB中,从而使得获取该地址变换条目的速度保持很快。在CP15中的C10用于控制TLB内容的锁定。
- MMU 可以将整个存储空间分为最多16个域,每个域对应一定的内存区域,该区域具有相同的访问控制属性。MMU中寄存器C3用于控制与域相关的属性的配置。
- 当存储访问失效时,MMU提供了相应的机制用于处理这种情况。在MMU中寄存器C5和寄存器C6用于支持这些机制。
禁止/使能MMU时应注意的问题 (重要) 应注意如下几点:
在使能MMU之前,要在内存中建立页表,同时,CP15中的各相关寄存器必须完成初始化。 如果使用的不是平板存储模式 (物理地址和虚拟地址相等) ,在禁止/使能MMU时,虚拟地址和物理地址的对应关系会发生改变,这时应该清除cache中的当前地址变换条目。 S3C2440/S3C2410中的MMU地址变换 ARM CPU上的地址转换过程涉及3个概念: 虚拟地址 (VA) 、变换后的虚拟地址 (MVA, modified virtrual address) 、物理地址 (PA) 。
没启动MMU时,CPU核、cache、MMU、外设等所有部件使用的都是物理地址。
启动MMU后,CPU核对外发出虚拟地址VA;VA被转换为MVA供cache、MMU使用,在这里MVA被转换为PA,最后使用PA读写实际设备。
ARM支持的存储块大小有以下几种:
段 (section) : 是大小为1M的存储块。 大页 (Large Pages) : 是大小为64KB的存储块。 小页 (Small Pages) : 是大小为4KB的存储块。 极小页 (Tiny Pages) : 是大小为1KB的存储块。 通过配置访问控制机制,还可以将大页分成大小为16KB的子页;将小页分成大小为1KB的子页;极小页不能再细分,只能以1KB大小的整页为单位。 MMU中的域 MMU中的域指的是一些段、大页或者小页的集合。ARM支持最多16个域,每个域的访问控制特性由CP15中的寄存器C3中的两位来控制,CP15中的寄存器C3的格式如下所示:
C3寄存器.png
其中每两位控制一个域的访问控制特性,其编码及对应的含义如下所示:
Paste_Image.png
作者: 放风筝的小小马 链接: https://www.jianshu.com/p/abb4b5aeb83b 來源: 简书 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
MMU内存管理单元介绍
前言 本篇文章简要阐述MMU的概念,以及以段地址的转换过程为例,简单说明MMU将虚拟地址转换成物理地址的过程。更多详细内容请查看《ARM-MMU(中文手册).pdf》。
-
MMU 概述 在ARM存储系统中,使用MMU实现虚拟地址到实际物理地址的映射。为何要实现这种映射? 首先就要从一个嵌入式系统的基本构成和运行方式着手。系统上电时,处理器的程序指针从0x0 (或者是由0Xffff_0000处高端启动) 处启动,顺序执行程序,在程序指针 (PC) 启动地址,属于非易失性存储器空间范围,如ROM、FLASH等。然而与上百兆的嵌入式处理器相比,FLASH、ROM等存储器响应速度慢,已成为提高系统性能的一个瓶颈。而SDRAM具有很高的响应速度,为何不使用SDRAM来执行程序呢?为了提高系统整体速度,可以这样设想,利用FLASH、ROM对系统进行配置,把真正的应用程序下载到SDRAM中运行,这样就可以提高系统的性能。然而这种想法又遇到了另外一个问题,当ARM处理器响应异常事件时,程序指针将要跳转到一个确定的位置,假设发生了IRQ中断,PC将指向0x18(如果为高端启动,则相应指向0vxffff_0018处),而此时0x18处仍为非易失性存储器所占据的位置,则程序的执行还是有一部分要在FLASH或者ROM中来执行的。那么我们可不可以使程序完全都SDRAM中运行那?答案是肯定的,这就引入了MMU,利用MMU,可把SDRAM的地址完全映射到0x0起始的一片连续地址空间,而把原来占据这片空间的FLASH或者ROM映射到其它不相冲突的存储空间位置。例如,FLASH的地址从0x0000_0000-0x00ff_ffff,而SDRAM的地址范围是0x3000_0000-0x31ff_ffff,则可把SDRAM地址映射为0x0000_0000-0x1fff_ffff而FLASH的地址可以映射到0x9000_0000-0x90ff_ffff (此处地址空间为空闲,未被占用) 。映射完成后,如果处理器发生异常,假设依然为IRQ中断,PC指针指向0x18处的地址,而这个时候PC实际上是从位于物理地址的0x3000_0018处读取指令。通过MMU的映射,则可实现程序完全运行在SDRAM之中。 在实际的应用中,可能会把两片不连续的物理地址空间分配给SDRAM。而在操作系统中,习惯于把SDRAM的空间连续起来,方便内存管理,且应用程序申请大块的内存时,操作系统内核也可方便地分配。通过MMU可实现不连续的物理地址空间映射为连续的虚拟地址空间。 操作系统内核或者一些比较关键的代码,一般是不希望被用户应用程序所访问的。通过MMU可以控制地址空间的访问权限,从而保护这些代码不被破坏。
-
MMU地址映射的实现 MMU的实现过程,实际上就是一个查表映射的过程。建立页表 (translate table) 是实现MMU功能不可缺少的一步。页表是位于系统的内存中,页表的每一项对应于一个虚拟地址到物理地址的映射。每一项的长度即是一个字的长度 (在ARM中,一个字的长度被定义为4字节) 。页表项除完成虚拟地址到物理地址的映射功能之外,还定义了访问权限和缓冲特性等。
2.1 映射存储块的分类 MMU 支持基于节或页的存储器访问, MMU 可以用下面四种大小进行映射: 节 ( Section ) 构成 1MB 的存储器块。 微页 ( Tiny page ) 构成 1KB 的存储器块。 小页 ( Small page ) 构成 4KB 的存储器块。 大页 ( Large page ) 构成 64KB 的存储器块。 其中对于节映射使用一级转换表就可以了,而对于微页、小页、大页则需要使用两级转换表。
2.2 转换过程 要知道虚拟内存机制必须了解ARM9中的3种地址: VA (虚地址) ,MVA (修正后虚地址) ,PA (物理地址)
- VA,是程序中的逻辑地址,0x00000000~0xFFFFFFFF。
- MVA,是修改后的虚拟地址。在ARM9里面,如果VA<32M,利用进程标识号PID转换得到MVA。过程如下:
if(VA < 32M) MVA = VA | ( PID«25 ) else MVA = VA
只是上面的过程是由硬件实现的。这样为VA进行了一级映射,为什么呢? 在linux系统里,每个进程的地址空间 0-4G,其中0-3G是进程独有的,称为用户空间,3G-4G是系统的,称为内核空间,所有进程共享。如果两个进程所用的VA有重叠,在切换进程时,为了把重叠的VA映射到不同的PA上,需要重建页表、使无效caches和TLBS。使用了MVA,使进程在VA相同的情况下,使用不同的MVA,进而PA也不同。这就是在VA与PA之间加上一次到MVA的映射的意义。 3) PA,物理地址,MVA通过MMU转换后的地址。 这里写图片描述
一级页表使用 4096 个描述符来表示 4GB 空间,每个描述符对应 1MB 的虚拟地址,存储它对应的 1MB 物理空间的起始地址,或者存储下一级页表的地址。每个描述符占 4 个字节,格式如下: 这里写图片描述
使用 MVA[31:20]来索引一级页表 (20-31 一共 12 位,2^12=4096,所以是4096 个描述符) 。其中段地址的转换流程如下图所示: 这里写图片描述 ①页表基址寄存器位[31:14]和 MVA[31:20]组成一个低两位为 0 的 32 位地址, MMU 利用这个地址找到段描述符。 ②取出段描述符的位[31:20] (段基址,section base address) ,它和 MVA[19:0]组成一个 32 位的物理地址 (这就是 MVA 对应的 PA)
2.3 TLB 从MVA 到 PA 的转换需要访问多次内存,大大降低了 CPU 的性能,有没有办法改进呢? 程序执行过程中,用到的指令和数据的地址往往集中在一个很小的范围内,其中的地址、数据经常使用,这是程序访问的局部性。由此,通过使用一个高速、容量相对较小的存储器来存储近期用到的页表条目 (段、大页、小页、极小页描述符) ,避免每次地址转换都到主存中查找,这样就大幅提高性能。这个存储器用来帮助快速地进行地址转换,成为转译查找缓存 (Translation Lookaside Buffers, TLB) 。 当 CPU 发出一个虚拟地址时,MMU 首先访问 TLB。如果 TLB 中含有能转换这个虚拟地址的描述符,则直接利用此描述符进行地址转换和权限检查,否则 MMU 访问页表找到描述符后再进行地址转换和权限检查,并将这个描述符填入TLB 中,下次再使用这个虚拟地址时就直接使用 TLB 用的描述符。 若转换成功,则称为"命中"。Linux 系统中,目前的"命中"率高达 90%以上,使分页机制带来的性能损失降低到了可接收的程度。若在 TLB 中进行查表转换失败,则退缩为一般的地址变换,概率小于 10%。
内存管理单元MMU简介 现代操作系统及CPU硬件中,都会提供内存管理单元 (memory management unit,MMU) 来进行内存的有效管理。内存管理算法有许多,从简单的裸机方法到分页和分段策略。各种算法都有其优缺点,为特定系统选择内存管理算法依赖于很多因素,特别是系统的硬件设计。
1 内存管理的目的 内存管理的目的是为了更好的使用内存 (似乎是废话-,-) 。 内存是现代操作系统运行的中心。操作系统中任何一个进程的运行都需要内存,但是,操作系统中的内存是有限的;另一方面,从安全的角度出发,进程都需要有自 己的内存空间,其他的进程都不能访问这个私有的空间;同时,内存的分配会导致内存碎片问题,严重影响计算机的性能。以上这三个问题就是一般内存管理算法所 需要处理的目标。
交换 内存保护 碎片问题 2 交换 进程需要在内存中执行,但进程可以暂时从内存中交换 (swap) 出去到备份存储上,当需要时再调回到内存中去。
m1.JPG
在基于优先级的交换调度算法中,如果一个更高优先级的进程来了且需要服务,内存管理可以交换出低优先级的进程,以便装入和执行更高优先级的进程。当高优先级的进程执行完毕之后,低优先级的进程可以交换回内存继续执行。这种交换有时被称之为滚出(roll out)、滚进(roll in)。
通常一个交换出的进程需要交换回它原来的内存空间。这一限制是由地址捆绑方式决定的。如果捆绑是在汇编时或加载时决定的,那么就不可以移动到不同的位置。如果捆绑是在运行时决定,由于物理地址是在运行时才确定,那么进程可以移到不同的地址空间。
交换的代价: 交换时间
交换时间主要是指转移时间,总的转移时间和所交换的内存空间成正比。交换不需要或只需要很少的磁头移动,简单的说,交换空间通常作为磁盘的一整块,且独立于文件系统 (如Linux的swap空间) ,因此使用就有可能很快。
交换需要花很多时间,而且进程执行时间却很少,故交换通常不执行,但只有在许多进程运行且内存吃紧时,交换才开始启动。
3 分页 3.1内存保护和内存碎片的背景 内存保护是指操作系统进程不受用户进程的影响,保护用户进程不受其他用户进程的影响。内存保护最基本的思路是进程使用逻辑地址空间,而内存管理单元所看的是物理地址。操作系统将逻辑地址分配给进程,MMU负责逻辑地址到物理地址的映射 (转换,捆绑) 。
值得注意的是对于指令 (程序) 和数据映射到内存地址可以在以下步骤地任意一步执行:
编译时: 如果编译时就知道进程将在内存中的驻留地址,那么就可以生成绝对代码。如MS-DOS的COM格式程序。 加载时: 如果编译时不知道程序将驻留在何处,那么编译器就必须要生成可重定位代码(relocatable code )。这种情况下,最后地址映射会延迟到加载时才确定,如果开始地址发生变换,必须重新加载程序,以引入新值。 执行时: 如果进程在执行时可以从一个内存段移到另一个内存段,那么映射必须延迟到执行时才进程。采用这种方法需要硬件的支持,目前绝大多数操作系统采用这种方法 (基于分页、分段等) 。 内存碎片是操作系统内存分配的产物。最初操作系统的内存是连续分配的,即进程A需要某一大小的内存空间,如200KB,操作系统就需要找出一块至少200KB的连续内存空间给进程A。随着系统的运行,进程终止时它将释放内存,该内存可以被操作系统分配给输入队列里的其他等待内存资源的进程。
可以想象,随着进程内存的分配和释放,最初的一大块连续内存空间被分成许多小片段,即使总的可用空间足够,但不再连续,因此产生的内存碎片。
一 个办法是不再对内存空间进行连续分配。这样只要有物理内存就可以为进程进行分配。而实际上,不进行连续分配只是相对的,因为完全这样做的代价太大。现实 中,往往定出一个最小的内存单元,内存分配是这最小单元的组合,单元内的地址是连续的,但各个单元不一定连续。这样的内存小单元有页和段。
当然,分段和分页也会产生碎片,但理论上每个碎片的大小不超过内存单元的大小。
3.2 分页 分页时一种内存管理方案,同时也提供了内存保护机制。它允许分配的物理内存地址可以是非连续的。
逻辑内存分为大小相等块的组合,这个块称之为页;物理内存则分为固定大小的帧(frame)。页大小应和帧大小相同,这是由硬件决定的。通常是2的幂,这样可以方便地将逻辑地址映射到物理地址。
基于分页的逻辑地址到物理地址的映射 m2.JPG
考虑32位地址。如果页大小是4KB,则需要12位来表示每一页中的某个具体地址,因此32位的逻辑地址中需要12位来对某一页中的具体地址寻址。这12位叫做页偏移。剩下的20位可以作为页码,可以有1M的页。逻辑地址可以表示为: m4.JPG 寻址时,根据页码P查页表,找到该页对应的帧,将帧号与页偏移 (也是帧偏移) 组合即得到物理地址。这样也说明了为什么页大小要等于帧大小,因为页数要等于帧数。
例如,页大小为4K,页码11对应的帧码是10,即表示是第10块物理帧,也偏移为5,则逻辑地址0X0000b 005对应的物理地址是0X0000a 005。
3.3 分页的内存保护 基于分页的操作系统在分配内存时分给进程所需要的页数,其对应物理内存的帧号同时装入该MMU的页表。同时页表上有一个标记为,指明该页是属于哪个进程的。甚至可以定义该页对于某个进程的读写权限。非法的读写操作会产生硬件陷阱 (或内存保护冲突) 。
3.4 分页的代价 由上一节可知分页是基于查找表的,而在内存中存储这个1M个项目的页表本身就带来了内存消耗和查找速度问题。于是,页表通常需要硬件的支持,即将页表写在硬件MMU的寄存器中。
如果页表比较小,那么页表写在寄存器中可以加快查找速度。但绝大多数当代的计算机页表都非常大。对于这些页表,采用快速寄存器来实现页表就不太合理了。
一种办法是使用TLB (translation look-aside buffer) 。TLB是关联的寄存器,TLB条目由两部分组成: 页号和帧号。 m5.JPG TLB只包含页表中的一小部分条目,整个页表还是保存在内存中。当CPU产生逻辑地址后,其页号提交给TLB。如果找到了页号,那同时也就找到了帧号,就可以访问物理内存;如果页号不在TLB中 (称为TLB失效) ,那就需要访问页表。在页表中找到帧号后,把页号和帧号增加到TLB中,这样下次再用时可以很快找到。如果TLB中条目已满,则操作系统会根据一个替换策略来替换条目。替换策略有很多,从最近最小使用替换到随机替换等。另外,有的TLB允许某些条目不被替换,如内核代码的条目。
有的TLB还在条目中保存地址空间保护标志符,用来唯一标志进程,以提供进程内存保护。
3.5 页表结构 对于32位以及64位逻辑地址的计算机来说,其页表实在太过庞大。为了压缩页表,一个简单的方法是使用层次化分页算法,就是将页表再分页。 (这实际上是一种索引的方法)
m6.JPG m7.JPG
即将2^20个页表项分为2^10个组,每个组里面有2^10项。这样只需要2K4=8K的页表空间,且查找速度也有很大提升。例如原先最坏情况下要查2^20次,现在最坏只要22^10次
内存管理单元MMU (memory management unit)
内存管理单元MMU (memory management unit) 的主要功能是虚拟地址 (virtual memory addresses) 到物理地址 (physical addresses) 的转换。除此之外,它还可以实现内存保护 (memory protection) 、缓存控制 (cache control) 、总线仲裁 (bus arbitration) 以及存储体切换 (bank switching) 。
工作机制 MMU功能图
CPU将要请求的虚拟地址传给MMU,然后MMU先在高速缓存TLB (Translation Lookaside Buffer) 查找转换关系,如果找到了相应的物理地址则直接访问;如果找不到则在地址转换表 (Translation Table) 里查找计算。
虚拟地址 现代的内存管理单元是以页的方式来分区虚拟地址空间 (the range of addresses used by the processor) 的。页的大小是2的n次方,通常为几KB。所以虚拟地址就被分为了两个部分: virtual page number和offset。
Page Lookups
页表项 (page table entry) 上面从虚拟页号在页表里找到的存放物理页表号的条目就是页表项 (PTE) 。PTE一般占1个字长,里面不仅包含了physical page number,还包含了重写标志位 (dirty bit) 、访问控制位 (accessed bit) 、允许读写的进程类型 (user/supervisor mode) 、是否可以被cached以及映射类型 (PTE最后两位) 。
映射 映射方式
映射方式有两种,段映射和页映射。段映射只用到一级页表,页映射用到一级页表和二级页表。
映射粒度
段映射的映射粒度有两种,1M section和16M supersection;页映射的映射粒度有4K small page、64K large page和过时的1K tiny page。
内存管理单元是介于处理器和片外存储器之间的中间层。提供对虚拟地址(VA)向物理地址(PA)的转换。一般封装于CPU芯片内部。因此虚拟地址一般只存在于CPU内部。
MMU工作流程:
<1> 用户程序执行背后的数据/指令地址等都是虚拟地址,虚拟地址由执行单元发出,被MMU拦截并转换为物理地址。从虚拟地址到物理地址这一过程被称为地址转换 (或映射) 。这一映射过程包含两个问题: 映射粒度和映射规则。
映射粒度: VA到PA映射的单位大小是页(Page),页大小一般为4k。映射不改变页内偏移。页帧(Page Frame)指物理内存中的一页内存,MMU虚实地址映射就是寻找物理页帧的过程。
映射规则: MMU的映射规则由页表(Page Table)来描述,即虚拟内存哪(几)个页映射到物理内存哪(几)个页帧。每个处理器进程都会维护一个页表,页表由一条条代表映射规则的记录组成,每一条称为一个页表条目 (Page Table Entry, PTE) ,页表存储在片外的主存上。为了加速映射效率,在MMU中存在一块页表缓存,被称为快表(Translation Lookaside Buffers)。MMU接收到虚拟地址后,首先在TLB中查找,如果找到该VA对应的PTE就直接转换,找不到再去外存页表查找,并置换进TLB。
虚拟地址由页号和页内偏移地址构成。在映射过程中不改变页内偏移 (4k页大小,则偏移有12bit) 。而对于页号,若一个32bit的虚拟地址,其页号占20bit,若总按页为页表的最小粒度。这样形成的单级页表可能过大。而实际情况是,很多时候可以映射到更大的内存块,因此往往会对页号分级,形成多级页表。
图2. linux虚拟地址的三级划分 (图片来源https://blog.csdn.net/ipmux/article/details/19167605) 简单说每次MMU根据虚拟地址查询页表都是一级级进行,先根据PGD的值查询,如果查到PGD的匹配,但后续PMD和PTE没有,就以2(offset+pte+pmd)=1M为粒度进行映射,后20bits全部是块内偏移,与物理地址相同。
MMU会对地址访问做限定,如内存保护 (禁止访问、可读、可写和可执行等) ,如果是禁止访问,MMU将向CPU发出页错误 (page fault) 的信号。
<2> 转换得到的物理地址通过地址总线去存储器中查找对应数据段 (缓存->主存->磁盘)
参考文献:
[1] 硬件篇之MMU
[2] 大页内存在虚拟化中的应用
物理地址和物理内存物理内存不需要我多解释,无非是真实的可见的物理存储器件,就像下面所画的一样,硬件电路通过总线能够依次查找到对应存储单元的值,物理上是高低电位,对应0/1表示。————————————————-———————————————— | | | | | | | | | A ————————————————-———————————————— | | | | | | | | | B ————————————————-———————————————— | | | | | | | | | C ————————————————-———————————————— | | | | | | | | | D ————————————————-———————————————— 1 2 3 4 5 6 7 8
比方这里A2就是第一排第二个存储单元,那么A2就是它的物理地址。假如现在你的电脑上插了1 个8GB的内存条,对应的就有8GB,也就是8589934592个内存单元。再假如现在你的电脑是32位的系统,那么cpu能寻找到每一个内存单元吗?如果能寻找到,那么对于32位操作系统最大的寻址能力是多少呢?对于64位的系统来说呢?这个问题下面解答。二、内存寻址假定没有内存管理单元(MMU)的支持下,对于32位操作系统而言,你给到CPU的地址是32位的,也就是一个long型的数据,所以最大的寻址能力就是2^32,也就是4 GB。所以,对于32位系统而言,你插个8 GB内存是有一半的空间,系统是没法寻找到的,等于浪费。而对于64位系统来说,寻址能力理论上可以达到2^64,但是,处理器所支持的RAM大小地址总线上的管脚限制,早期的Intel处理器只能支持4 GB寻址,从奔腾pro开始才出现了物理地址扩展的机制来支持更大内存空间,所以如果没有这个机制,或者这个机制被关闭,对于手机来说经常如此,那么内存寻址仍然只有4 GB。但是,现代计算机都是会存在MMU的,这是一个硬件电路,能够将一个逻辑地址转换成一个线性地址,也就是虚拟地址。三、逻辑地址和线性地址逻辑地址,就是指机器语言指令中用来指定一个操作数或一条指令的地址,由一个段(segment)和偏移量(offset)组成,说地直白点就是CPU拿到的地址。线性地址,也叫虚拟地址,就是题主所问的虚拟地址。值得注意的是这个地址就是一个32位无符号的整型数,所以虚拟地址空间总共就是4 GB大小。系统中的每个进程所使用的地址就是线性地址或者说虚拟地址,而不是什么逻辑地址,更不是物理地址,所以对每个独立的进程来说,线性空间大小是4 GB是没有错的,且其中0-1GB的地址空间给予内核访问,其它3GB由每个进程自己访问。那是不是说一个进程就只能访问4GB的物理内存大小呢?答案是否定的,具体访问到哪个物理地址要看MMU将线性地址转换后的物理地址才能知道,所以有可能两个进程的地址同时访问同一个物理地址,这在物理地址很小的情况下是经常会发生的事情。当然,同一时刻,一个物理内存单元只可能由某个进程来访问,至于具体原理,这个MMU来实现的,这里不细讲。四、地址转换有了MMU,CPU拿到的逻辑地址就可以经过它来找到对应的物理地址了。MMU有两个硬件电路单元,一个称之为分段单元(segmentation unit)、一个称之为分页单元(paging unit),下面是它的工作原理:
--------------- --------------
逻辑地址 ----> | 分段单元 | ----> 线性地址 ----> | 分页单元 | ----> 物理地址
--------------- --------------
所以,如果系统、CPU、MMU和内存坐在一起,那肯定会发生下面的对话:系统: CPU我给你个逻辑地址0xff84ed43,你去找到这个人CPU: 好的系统,我去问问MMU。 MMU,我这里有个地址0xff84ed43,你帮忙找一下MMU: 好的,请求分段单元,这个地址你先找到他家所在街道的地址分段单元: 报告,已经找到了他家所在的街道地址,地址是0x56ac21feMMU: 好的,请求分页单元,这个是他家的街道地址,你找到他家住几号。分页单元: 报告,已经找到了,他家具体地址是0x12345678CPU: 谢谢,我这就去找他
内存屏障 Memory barrier
也称内存栅栏,内存栅障,屏障指令等,是一类同步屏障指令,是CPU或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作。
https://ieevee.com/assets/2018-01-28-gogc.html
虚拟内存的那点事儿
概述 我们都知道一个进程是与其他进程共享CPU和内存资源的。正因如此,操作系统需要有一套完善的内存管理机制才能防止进程之间内存泄漏的问题。
为了更加有效地管理内存并减少出错,现代操作系统提供了一种对主存的抽象概念,即是虚拟内存 (Virtual Memory) 。虚拟内存为每个进程提供了一个一致的、私有的地址空间,它让每个进程产生了一种自己在独享主存的错觉 (每个进程拥有一片连续完整的内存空间) 。
理解不深刻的人会认为虚拟内存只是"使用硬盘空间来扩展内存"的技术,这是不对的。虚拟内存的重要意义是它定义了一个连续的虚拟地址空间,使得程序的编写难度降低。并且,把内存扩展到硬盘空间只是使用虚拟内存的必然结果,虚拟内存空间会存在硬盘中,并且会被内存缓存 (按需) ,有的操作系统还会在内存不够的情况下,将某一进程的内存全部放入硬盘空间中,并在切换到该进程时再从硬盘读取 (这也是为什么Windows会经常假死的原因…) 。
虚拟内存主要提供了如下三个重要的能力:
它把主存看作为一个存储在硬盘上的虚拟地址空间的高速缓存,并且只在主存中缓存活动区域 (按需缓存) 。
它为每个进程提供了一个一致的地址空间,从而降低了程序员对内存管理的复杂性。
它还保护了每个进程的地址空间不会被其他进程破坏。
介绍了虚拟内存的基本概念之后,接下来的内容将会从虚拟内存在硬件中如何运作逐渐过渡到虚拟内存在操作系统 (Linux) 中的实现。
本文作者为SylvanasSun(sylvanas.sun@gmail.com),首发于SylvanasSun’s Blog。 原文链接: https://sylvanassun.github.io/2017/10/29/2017-10-29-virtual_memory/ (转载请务必保留本段声明,并且保留超链接。)
CPU寻址 内存通常被组织为一个由M个连续的字节大小的单元组成的数组,每个字节都有一个唯一的物理地址 (Physical Address PA) ,作为到数组的索引。CPU访问内存最简单直接的方法就是使用物理地址,这种寻址方式被称为物理寻址。
现代处理器使用的是一种称为虚拟寻址 (Virtual Addressing) 的寻址方式。使用虚拟寻址,CPU需要将虚拟地址翻译成物理地址,这样才能访问到真实的物理内存。
虚拟寻址
虚拟寻址需要硬件与操作系统之间互相合作。CPU中含有一个被称为内存管理单元 (Memory Management Unit, MMU) 的硬件,它的功能是将虚拟地址转换为物理地址。MMU需要借助存放在内存中的页表来动态翻译虚拟地址,该页表由操作系统管理。
页表 虚拟内存空间被组织为一个存放在硬盘上的M个连续的字节大小的单元组成的数组,每个字节都有一个唯一的虚拟地址,作为到数组的索引 (这点其实与物理内存是一样的) 。
操作系统通过将虚拟内存分割为大小固定的块来作为硬盘和内存之间的传输单位,这个块被称为虚拟页 (Virtual Page, VP) ,每个虚拟页的大小为P=2^p字节。物理内存也会按照这种方法分割为物理页 (Physical Page, PP) ,大小也为P字节。
CPU在获得虚拟地址之后,需要通过MMU将虚拟地址翻译为物理地址。而在翻译的过程中还需要借助页表,所谓页表就是一个存放在物理内存中的数据结构,它记录了虚拟页与物理页的映射关系。
页表是一个元素为页表条目 (Page Table Entry, PTE) 的集合,每个虚拟页在页表中一个固定偏移量的位置上都有一个PTE。下面是PTE仅含有一个有效位标记的页表结构,该有效位代表这个虚拟页是否被缓存在物理内存中。
虚拟页VP 0、VP 4、VP 6、VP 7被缓存在物理内存中,虚拟页VP 2和VP 5被分配在页表中,但并没有缓存在物理内存,虚拟页VP 1和VP 3还没有被分配。
在进行动态内存分配时,例如malloc()函数或者其他高级语言中的new关键字,操作系统会在硬盘中创建或申请一段虚拟内存空间,并更新到页表 (分配一个PTE,使该PTE指向硬盘上这个新创建的虚拟页) 。
由于CPU每次进行地址翻译的时候都需要经过PTE,所以如果想控制内存系统的访问,可以在PTE上添加一些额外的许可位 (例如读写权限、内核权限等) ,这样只要有指令违反了这些许可条件,CPU就会触发一个一般保护故障,将控制权传递给内核中的异常处理程序。一般这种异常被称为"段错误 (Segmentation Fault) “。
页命中 页命中
如上图所示,MMU根据虚拟地址在页表中寻址到了PTE 4,该PTE的有效位为1,代表该虚拟页已经被缓存在物理内存中了,最终MMU得到了PTE中的物理内存地址 (指向PP 1) 。
缺页 缺页
如上图所示,MMU根据虚拟地址在页表中寻址到了PTE 2,该PTE的有效位为0,代表该虚拟页并没有被缓存在物理内存中。虚拟页没有被缓存在物理内存中 (缓存未命中) 被称为缺页。
当CPU遇见缺页时会触发一个缺页异常,缺页异常将控制权转向操作系统内核,然后调用内核中的缺页异常处理程序,该程序会选择一个牺牲页,如果牺牲页已被修改过,内核会先将它复制回硬盘 (采用写回机制而不是直写也是为了尽量减少对硬盘的访问次数) ,然后再把该虚拟页覆盖到牺牲页的位置,并且更新PTE。
当缺页异常处理程序返回时,它会重新启动导致缺页的指令,该指令会把导致缺页的虚拟地址重新发送给MMU。由于现在已经成功处理了缺页异常,所以最终结果是页命中,并得到物理地址。
这种在硬盘和内存之间传送页的行为称为页面调度 (paging) : 页从硬盘换入内存和从内存换出到硬盘。当缺页异常发生时,才将页面换入到内存的策略称为按需页面调度 (demand paging) ,所有现代操作系统基本都使用的是按需页面调度的策略。
虚拟内存跟CPU高速缓存 (或其他使用缓存的技术) 一样依赖于局部性原则。虽然处理缺页消耗的性能很多 (毕竟还是要从硬盘中读取) ,而且程序在运行过程中引用的不同虚拟页的总数可能会超出物理内存的大小,但是局部性原则保证了在任意时刻,程序将趋向于在一个较小的活动页面 (active page) 集合上工作,这个集合被称为工作集 (working set) 。根据空间局部性原则 (一个被访问过的内存地址以及其周边的内存地址都会有很大几率被再次访问) 与时间局部性原则 (一个被访问过的内存地址在之后会有很大几率被再次访问) ,只要将工作集缓存在物理内存中,接下来的地址翻译请求很大几率都在其中,从而减少了额外的硬盘流量。
如果一个程序没有良好的局部性,将会使工作集的大小不断膨胀,直至超过物理内存的大小,这时程序会产生一种叫做抖动 (thrashing) 的状态,页面会不断地换入换出,如此多次的读写硬盘开销,性能自然会十分"恐怖”。所以,想要编写出性能高效的程序,首先要保证程序的时间局部性与空间局部性。
多级页表 我们目前为止讨论的只是单页表,但在实际的环境中虚拟空间地址都是很大的 (一个32位系统的地址空间有2^32 = 4GB,更别说64位系统了) 。在这种情况下,使用一个单页表明显是效率低下的。
常用方法是使用层次结构的页表。假设我们的环境为一个32位的虚拟地址空间,它有如下形式:
虚拟地址空间被分为4KB的页,每个PTE都是4字节。
内存的前2K个页面分配给了代码和数据。
之后的6K个页面还未被分配。
再接下来的1023个页面也未分配,其后的1个页面分配给了用户栈。
下图是为该虚拟地址空间构造的二级页表层次结构 (真实情况中多为四级或更多) ,一级页表 (1024个PTE正好覆盖4GB的虚拟地址空间,同时每个PTE只有4字节,这样一级页表与二级页表的大小也正好与一个页面的大小一致都为4KB) 的每个PTE负责映射虚拟地址空间中一个4MB的片 (chunk) ,每一片都由1024个连续的页面组成。二级页表中的每个PTE负责映射一个4KB的虚拟内存页面。
这个结构看起来很像是一个B-Tree,这种层次结构有效的减缓了内存要求:
如果一个一级页表的一个PTE是空的,那么相应的二级页表也不会存在。这代表一种巨大的潜在节约 (对于一个普通的程序来说,虚拟地址空间的大部分都会是未分配的) 。
只有一级页表才总是需要缓存在内存中的,这样虚拟内存系统就可以在需要时创建、页面调入或调出二级页表 (只有经常使用的二级页表才会被缓存在内存中) ,这就减少了内存的压力。
地址翻译的过程 从形式上来说,地址翻译是一个N元素的虚拟地址空间中的元素和一个M元素的物理地址空间中元素之间的映射。
下图为MMU利用页表进行寻址的过程:
页表基址寄存器 (PTBR) 指向当前页表。一个n位的虚拟地址包含两个部分,一个p位的虚拟页面偏移量 (Virtual Page Offset, VPO) 和一个 (n - p) 位的虚拟页号 (Virtual Page Number, VPN) 。
MMU根据VPN来选择对应的PTE,例如VPN 0代表PTE 0、VPN 1代表PTE 1….因为物理页与虚拟页的大小是一致的,所以物理页面偏移量 (Physical Page Offset, PPO) 与VPO是相同的。那么之后只要将PTE中的物理页号 (Physical Page Number, PPN) 与虚拟地址中的VPO串联起来,就能得到相应的物理地址。
多级页表的地址翻译也是如此,只不过因为有多个层次,所以VPN需要分成多段。假设有一个k级页表,虚拟地址会被分割成k个VPN和1个VPO,每个VPN i都是一个到第i级页表的索引。为了构造物理地址,MMU需要访问k个PTE才能拿到对应的PPN。
TLB 页表是被缓存在内存中的,尽管内存的速度相对于硬盘来说已经非常快了,但与CPU还是有所差距。为了防止每次地址翻译操作都需要去访问内存,CPU使用了高速缓存与TLB来缓存PTE。
在最糟糕的情况下 (不包括缺页) ,MMU需要访问内存取得相应的PTE,这个代价大约为几十到几百个周期,如果PTE凑巧缓存在L1高速缓存中 (如果L1没有还会从L2中查找,不过我们忽略多级缓冲区的细节) ,那么性能开销就会下降到1个或2个周期。然而,许多系统甚至需要消除即使这样微小的开销,TLB由此而生。
TLB (Translation Lookaside Buffer, TLB) 被称为翻译后备缓冲器或翻译旁路缓冲器,它是MMU中的一个缓冲区,其中每一行都保存着一个由单个PTE组成的块。用于组选择和行匹配的索引与标记字段是从VPN中提取出来的,如果TLB中有T = 2^t个组,那么TLB索引 (TLBI) 是由VPN的t个最低位组成的,而TLB标记 (TLBT) 是由VPN中剩余的位组成的。
下图为地址翻译的流程 (TLB命中的情况下) :
第一步,CPU将一个虚拟地址交给MMU进行地址翻译。
第二步和第三步,MMU通过TLB取得相应的PTE。
第四步,MMU通过PTE翻译出物理地址并将它发送给高速缓存/内存。
第五步,高速缓存返回数据到CPU (如果缓存命中的话,否则还需要访问内存) 。
当TLB未命中时,MMU必须从高速缓存/内存中取出相应的PTE,并将新取得的PTE存放到TLB (如果TLB已满会覆盖一个已经存在的PTE) 。
Linux中的虚拟内存系统 Linux为每个进程维护了一个单独的虚拟地址空间。虚拟地址空间分为内核空间与用户空间,用户空间包括代码、数据、堆、共享库以及栈,内核空间包括内核中的代码和数据结构,内核空间的某些区域被映射到所有进程共享的物理页面。Linux也将一组连续的虚拟页面 (大小等于内存总量) 映射到相应的一组连续的物理页面,这种做法为内核提供了一种便利的方法来访问物理内存中任何特定的位置。
Linux将虚拟内存组织成一些区域 (也称为段) 的集合,区域的概念允许虚拟地址空间有间隙。一个区域就是已经存在着的已分配的虚拟内存的连续片 (chunk) 。例如,代码段、数据段、堆、共享库段,以及用户栈都属于不同的区域,每个存在的虚拟页都保存在某个区域中,而不属于任何区域的虚拟页是不存在的,也不能被进程所引用。
内核为系统中的每个进程维护一个单独的任务结构 (task_struct) 。任务结构中的元素包含或者指向内核运行该进程所需的所有信息 (PID、指向用户栈的指针、可执行目标文件的名字、程序计数器等) 。
mm_struct: 描述了虚拟内存的当前状态。pgd 指向一级页表的基址 (当内核运行这个进程时,pgd会被存放在CR3控制寄存器,也就是页表基址寄存器中) ,mmap指向一个vm_area_structs的链表,其中每个vm_area_structs都描述了当前虚拟地址空间的一个区域。
vm_starts: 指向这个区域的起始处。
vm_end: 指向这个区域的结束处。
vm_prot: 描述这个区域内包含的所有页的读写许可权限。
vm_flags: 描述这个区域内的页面是与其他进程共享的,还是这个进程私有的以及一些其他信息。
vm_next: 指向链表的下一个区域结构。
内存映射 Linux通过将一个虚拟内存区域与一个硬盘上的文件关联起来,以初始化这个虚拟内存区域的内容,这个过程称为内存映射 (memory mapping) 。这种将虚拟内存系统集成到文件系统的方法可以简单而高效地把程序和数据加载到内存中。
一个区域可以映射到一个普通硬盘文件的连续部分,例如一个可执行目标文件。文件区 (section) 被分成页大小的片,每一片包含一个虚拟页的初始内容。由于按需页面调度的策略,这些虚拟页面没有实际交换进入物理内存,直到CPU引用的虚拟地址在该区域的范围内。如果区域比文件区要大,那么就用零来填充这个区域的余下部分。
一个区域也可以映射到一个匿名文件,匿名文件是由内核创建的,包含的全是二进制零。当CPU第一次引用这样一个区域内的虚拟页面时,内核就在物理内存中找到一个合适的牺牲页面,如果该页面被修改过,就先将它写回到硬盘,之后用二进制零覆盖牺牲页并更新页表,将这个页面标记为已缓存在内存中的。
简单的来说: 普通文件映射就是将一个文件与一块内存建立起映射关系,对该文件进行IO操作可以绕过内核直接在用户态完成 (用户态在该虚拟地址区域读写就相当于读写这个文件) 。匿名文件映射一般在用户空间需要分配一段内存来存放数据时,由内核创建匿名文件并与内存进行映射,之后用户态就可以通过操作这段虚拟地址来操作内存了。匿名文件映射最熟悉的应用场景就是动态内存分配 (malloc()函数) 。
Linux很多地方都采用了"懒加载"机制,自然也包括内存映射。不管是普通文件映射还是匿名映射,Linux只会先划分虚拟内存地址。只有当CPU第一次访问该区域内的虚拟地址时,才会真正的与物理内存建立映射关系。
只要虚拟页被初始化了,它就在一个由内核维护的交换文件 (swap file) 之间换来换去。交换文件又称为交换空间 (swap space) 或交换区域 (swap area) 。swap区域不止用于页交换,在物理内存不够的情况下,还会将部分内存数据交换到swap区域 (使用硬盘来扩展内存) 。
共享对象 虚拟内存系统为每个进程提供了私有的虚拟地址空间,这样可以保证进程之间不会发生错误的读写。但多个进程之间也含有相同的部分,例如每个C程序都使用到了C标准库,如果每个进程都在物理内存中保持这些代码的副本,那会造成很大的内存资源浪费。
内存映射提供了共享对象的机制,来避免内存资源的浪费。一个对象被映射到虚拟内存的一个区域,要么是作为共享对象,要么是作为私有对象的。
如果一个进程将一个共享对象映射到它的虚拟地址空间的一个区域内,那么这个进程对这个区域的任何写操作,对于那些也把这个共享对象映射到它们虚拟内存的其他进程而言,也是可见的。相对的,对一个映射到私有对象的区域的任何写操作,对于其他进程来说是不可见的。一个映射到共享对象的虚拟内存区域叫做共享区域,类似地,也有私有区域。
为了节约内存,私有对象开始的生命周期与共享对象基本上是一致的 (在物理内存中只保存私有对象的一份副本) ,并使用写时复制的技术来应对多个进程的写冲突。
只要没有进程试图写它自己的私有区域,那么多个进程就可以继续共享物理内存中私有对象的一个单独副本。然而,只要有一个进程试图对私有区域的某一页面进行写操作,就会触发一个保护异常。在上图中,进程B试图对私有区域的一个页面进行写操作,该操作触发了保护异常。异常处理程序会在物理内存中创建这个页面的一个新副本,并更新PTE指向这个新的副本,然后恢复这个页的可写权限。
还有一个典型的例子就是fork()函数,该函数用于创建子进程。当fork()函数被当前进程调用时,内核会为新进程创建各种必要的数据结构,并分配给它一个唯一的PID。为了给新进程创建虚拟内存,它复制了当前进程的mm_struct、vm_area_struct和页表的原样副本。并将两个进程的每个页面都标为只读,两个进程中的每个区域都标记为私有区域 (写时复制) 。
这样,父进程和子进程的虚拟内存空间完全一致,只有当这两个进程中的任一个进行写操作时,再使用写时复制来保证每个进程的虚拟地址空间私有的抽象概念。
动态内存分配 虽然可以使用内存映射 (mmap()函数) 来创建和删除虚拟内存区域来满足运行时动态内存分配的问题。然而,为了更好的移植性与便利性,还需要一个更高层面的抽象,也就是动态内存分配器 (dynamic memory allocator) 。
动态内存分配器维护着一个进程的虚拟内存区域,也就是我们所熟悉的"堆 (heap) “,内核中还维护着一个指向堆顶的指针brk (break) 。动态内存分配器将堆视为一个连续的虚拟内存块 (chunk) 的集合,每个块有两种状态,已分配和空闲。已分配的块显式地保留为供应用程序使用,空闲块则可以用来进行分配,它的空闲状态直到它显式地被应用程序分配为止。已分配的块要么被应用程序显式释放,要么被垃圾回收器所释放。
本文只讲解动态内存分配的一些概念,关于动态内存分配器的实现已经超出了本文的讨论范围。如果有对它感兴趣的同学,可以去参考dlmalloc的源码,它是由Doug Lea (就是写Java并发包的那位) 实现的一个设计巧妙的内存分配器,而且源码中的注释十分多。
内存碎片 造成堆的空间利用率很低的主要原因是一种被称为碎片 (fragmentation) 的现象,当虽然有未使用的内存但这块内存并不能满足分配请求时,就会产生碎片。有以下两种形式的碎片:
内部碎片: 在一个已分配块比有效载荷大时发生。例如,程序请求一个5字 (这里我们不纠结字的大小,假设一个字为4字节,堆的大小为16字并且要保证边界双字对齐) 的块,内存分配器为了保证空闲块是双字边界对齐的 (具体实现中对齐的规定可能略有不同,但对齐是肯定会有的) ,只好分配一个6字的块。在本例中,已分配块为6字,有效载荷为5字,内部碎片为已分配块减去有效载荷,为1字。
外部碎片: 当空闲内存合计起来足够满足一个分配请求,但是没有一个单独的空闲块足够大到可以来处理这个请求时发生。外部碎片难以量化且不可预测,所以分配器通常采用启发式策略来试图维持少量的大空闲块,而不是维持大量的小空闲块。分配器也会根据策略与分配请求的匹配来分割空闲块与合并空闲块 (必须相邻) 。
空闲链表 分配器将堆组织为一个连续的已分配块和空闲块的序列,该序列被称为空闲链表。空闲链表分为隐式空闲链表与显式空闲链表。
隐式空闲链表,是一个单向链表,并且每个空闲块仅仅是通过头部中的大小字段隐含地连接着的。
显式空闲链表,即是将空闲块组织为某种形式的显式数据结构 (为了更加高效地合并与分割空闲块) 。例如,将堆组织为一个双向空闲链表,在每个空闲块中,都包含一个前驱节点的指针与后继节点的指针。
查找一个空闲块一般有如下几种策略:
首次适配: 从头开始搜索空闲链表,选择第一个遇见的合适的空闲块。它的优点在于趋向于将大的空闲块保留在链表的后面,缺点是它趋向于在靠近链表前部处留下碎片。
下一次适配: 每次从上一次查询结束的地方开始进行搜索,直到遇见合适的空闲块。这种策略通常比首次适配效率高,但是内存利用率则要低得多了。
最佳适配: 检查每个空闲块,选择适合所需请求大小的最小空闲块。最佳适配的内存利用率是三种策略中最高的,但它需要对堆进行彻底的搜索。
对一个链表进行查找操作的效率是线性的,为了减少分配请求对空闲块匹配的时间,分配器通常采用分离存储 (segregated storage) 的策略,即是维护多个空闲链表,其中每个链表的块有大致相等的大小。
一种简单的分离存储策略: 分配器维护一个空闲链表数组,然后将所有可能的块分成一些等价类 (也叫做大小类 (size class) ) ,每个大小类代表一个空闲链表,并且每个大小类的空闲链表包含大小相等的块,每个块的大小就是这个大小类中最大元素的大小 (例如,某个大小类的范围定义为 (17~32) ,那么这个空闲链表全由大小为32的块组成) 。
当有一个分配请求时,我们检查相应的空闲链表。如果链表非空,那么就分配其中第一块的全部。如果链表为空,分配器就向操作系统请求一个固定大小的额外内存片,将这个片分成大小相等的块,然后将这些块链接起来形成新的空闲链表。
要释放一个块,分配器只需要简单地将这个块插入到相应的空闲链表的头部。
垃圾回收 在编写C程序时,一般只能显式地分配与释放堆中的内存 (malloc()与free()) ,程序员不仅需要分配内存,还需要负责内存的释放。
许多现代编程语言都内置了自动内存管理机制 (通过引入自动内存管理库也可以让C/C++实现自动内存管理) ,所谓自动内存管理,就是自动判断不再需要的堆内存 (被称为垃圾内存) ,然后自动释放这些垃圾内存。
自动内存管理的实现是垃圾收集器 (garbage collector) ,它是一种动态内存分配器,它会自动释放应用程序不再需要的已分配块。
垃圾收集器一般采用以下两种 (之一) 的策略来判断一块堆内存是否为垃圾内存:
引用计数器: 在数据的物理空间中添加一个计数器,当有其他数据与其相关时 (引用) ,该计数器加一,反之则减一。通过定期检查计数器的值,只要为0则认为是垃圾内存,可以释放它所占用的已分配块。使用引用计数器,实现简单直接,但缺点也很明显,它无法回收循环引用的两个对象 (假设有对象A与对象B,它们2个互相引用,但实际上对象A与对象B都已经是没用的对象了) 。
可达性分析: 垃圾收集器将堆内存视为一张有向图,然后选出一组根节点 (例如,在Java中一般为类加载器、全局变量、运行时常量池中的引用类型变量等) ,根节点必须是足够"活跃"的对象。然后计算从根节点集合出发的可达路径,只要从根节点出发不可达的节点,都视为垃圾内存。
垃圾收集器进行回收的算法有如下几种:
标记清除: 该算法分为标记 (mark) 和清除 (sweep) 两个阶段。首先标记出所有需要回收的对象,然后在标记完成后统一回收所有被标记的对象。标记清除算法实现简单,但它的效率不高,而且会产生许多内存碎片。
标记-整理: 标记-整理与标记清除算法基本一致,只不过后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉边界以外的内存。
复制: 将程序所拥有的内存空间划分为大小相等的两块,每次都只使用其中的一块。当这一块的内存用完了,就把还存活着的对象复制到另一块内存上,然后将已使用过的内存空间进行清理。这种方法不必考虑内存碎片问题,但内存利用率很低。这个比例不是绝对的,像HotSpot虚拟机为了避免浪费,将内存划分为Eden空间与两个Survivor空间,每次都只使用Eden和其中一个Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性地复制到另外一个Survivor空间上,然后清理掉Eden和刚才使用过的Survivor空间。HotSpot虚拟机默认的Eden和Survivor的大小比例为8: 1,只有10%的内存空间会被闲置浪费。
分代: 分代算法根据对象的存活周期的不同将内存划分为多块,这样就可以对不同的年代采用不同的回收算法。一般分为新生代与老年代,新生代存放的是存活率较低的对象,可以采用复制算法;老年代存放的是存活率较高的对象,如果使用复制算法,那么内存空间会不够用,所以必须使用标记清除或标记-整理算法。
总结 虚拟内存是对内存的一个抽象。支持虚拟内存的CPU需要通过虚拟寻址的方式来引用内存中的数据。CPU加载一个虚拟地址,然后发送给MMU进行地址翻译。地址翻译需要硬件与操作系统之间紧密合作,MMU借助页表来获得物理地址。
首先,MMU先将虚拟地址发送给TLB以获得PTE (根据VPN寻址) 。
如果恰好TLB中缓存了该PTE,那么就返回给MMU,否则MMU需要从高速缓存/内存中获得PTE,然后更新缓存到 TLB。
MMU获得了PTE,就可以从PTE中获得对应的PPN,然后结合VPO构造出物理地址。
如果在PTE中发现该虚拟页没有缓存在内存,那么会触发一个缺页异常。缺页异常处理程序会把虚拟页缓存进物理内存,并更新PTE。异常处理程序返回后,CPU会重新加载这个虚拟地址,并进行翻译。
虚拟内存系统简化了内存管理、链接、加载、代码和数据的共享以及访问权限的保护:
简化链接,独立的地址空间允许每个进程的内存映像使用相同的基本格式,而不管代码和数据实际存放在物理内存的何处。
简化加载,虚拟内存使向内存中加载可执行文件和共享对象文件变得更加容易。
简化共享,独立的地址空间为操作系统提供了一个管理用户进程和内核之间共享的一致机制。
访问权限保护,每个虚拟地址都要经过查询PTE的过程,在PTE中设定访问权限的标记位从而简化内存的权限保护。
操作系统通过将虚拟内存与文件系统结合的方式,来初始化虚拟内存区域,这个过程称为内存映射。应用程序显式分配内存的区域叫做堆,通过动态内存分配器来直接操作堆内存。
参考文献 CS:APP3e, Bryant and O’Hallaron
Virtual memory - Wikipedia
Garbage collection (computer science) - Wikipedia
线性地址 (linear address)
内存就是一个数据货架。内存有一个最小的存储单位,大多数都是一个字节。内存用内存地址 (memory address)来为每个字节的数据顺序编号。因此,内存地址说明了数据在内存中的位置。内存地址从0开始,每次增加1。这种线性增加的存储器地址称为线性地址 (linear address)
作者: VizXu 链接: https://www.zhihu.com/question/290504400/answer/485124116 来源: 知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
https://nieyong.github.io/wiki_cpu/CPU%E4%BD%93%E7%B3%BB%E6%9E%B6%E6%9E%84-MMU.html
作者: u753b 链接: https://www.zhihu.com/question/290504400/answer/633251677 来源: 知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
https://sylvanassun.github.io/2017/10/29/2017-10-29-virtual_memory/
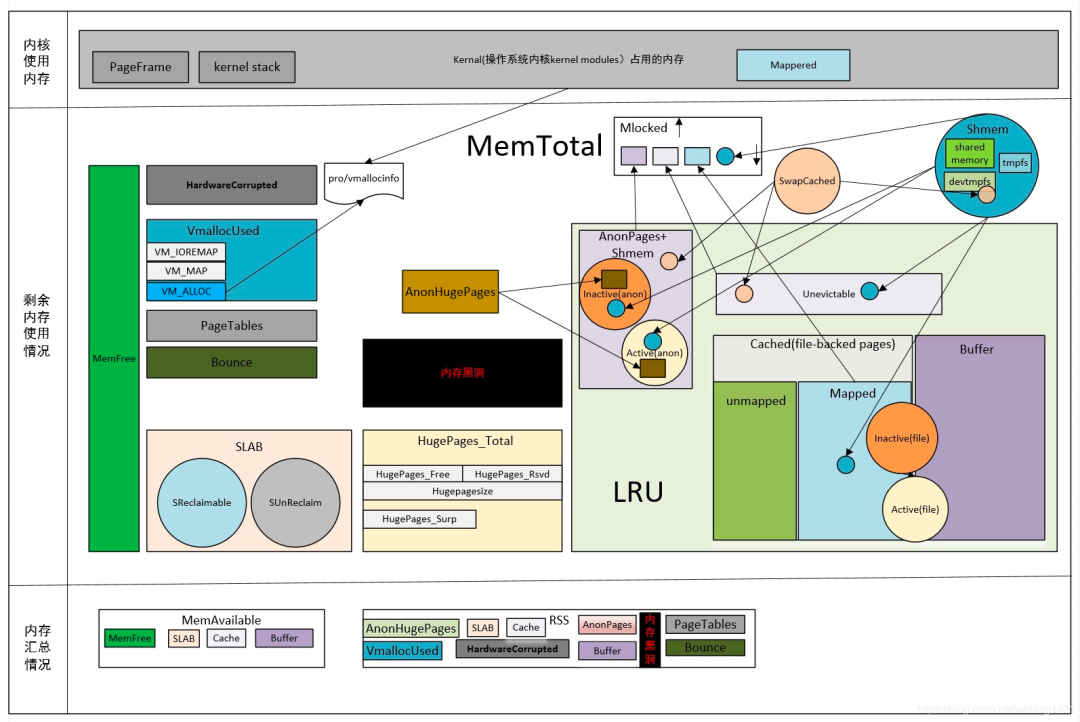
https://zhuanlan.zhihu.com/p/43526907
https://www.eet-china.com/mp/a87720.html
https://www.hi-linux.com/posts/42797.html
金士顿型号解码器
https://www.kingston.com.cn/cn/memory/memory-part-number-decoder
低电压版
普通的 DDR3 内存条额定工作电压是 1.5V,而 DDR3L 的电压市面上有两种标注版本,一种是 1.35V,另一种是1.28V。不过近年又出现一种DDR3U的内存,Ultra Low Voltage DDR3,意思是超低电压DDR3内存,其工作电压可以低至1.25V,但市场占有率不太高。